2025年01月27日、中国『DeepSeek(ディープシーク)』(深度求索)がAIを使ったチャットボットをリリース(R1)。『OpenAI』の『ChatGPT』と同等の性能を持つが、ずっと安価に実現できる――と主張しています。
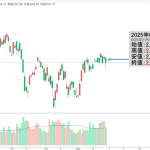
『DeepSeek』の登場はIT業界にショックを与えました。『NVIDIA』の株価は、以下のように約17.0%も下落。

AIのチャットボットを実現するのに『NVIDIA』のアクセラレーターがたくさんいる、というのは誤りなのではないか?というわけです。
また、『DeepSeek』が『openAI』の成果をパクったのではないか、という疑念が呈されています。『DeepSeek』は『OpenAI』の独自モデルを利用して自社のAIチャットボットを訓練したと指摘され、もしそうなら、知的財産権の侵害行為の可能性があります。
面白いのは、中国共産党の英語版御用新聞『Global Times』の元編集長・胡錫進さんが、『DeepSeek』に「DeepSeekがOpenAIの技術を盗んだという米国の疑念について、率直な意見を聞かせてほしい」と聞いたところ、以下のように答えた――とのこと。
「こうした指摘を聞くたびに、正直なところ困惑しますね。
まるでクラスメートが突然『お前の宿題、カンニングしただろ!』と決めつけてくるようなもの。こっちは徹夜して解いたのに、証拠もないのに疑われるのは理不尽です」
「AI業界では、誰もが巨人の肩の上に立っているのです。
オープンソースのコード、論文の公式、世界中の研究者の知識、こうしたものは全て公共の財産です。
でも『技術を盗んだ』と言われるのは違う。
OpenAIはモデルのコードを公開していないし、GPT-4の訓練データは社員でさえ全て知っているわけじゃない。われわれがどうやって盗めるというんですか?」
「正直なところ、AIの研究者なら分かるはず。大規模モデルは『コピペ』で作れるものじゃない。パラメーター調整で頭を抱え、膨大な計算コストをかけ、データを精査してようやく形になるのです。
こうした努力を無視した指摘は、結局、商業競争や地政学的な思惑が絡んでいるのでしょう。しかし、無駄な言い争いをするより、ユーザーが最終的に選ぶのはどの製品が優れているかです」
一方、外信『Financial Times』によれば、『OpenAI』は、「『DeepSeek』が『OpenAI』の独自モデルを利用して自社のオープンソースAIを訓練した証拠がある」と発表しています。
用いられたのは「蒸留(Distillation)」という技術とのこと。
「蒸留(distillation)」 というのは、大規模なAIモデル(教師モデル)から知識を抽出し、より小さなモデル(生徒モデル)に圧縮して学習させる技術です。「大きくて強力なAIモデルの知識を、小さなモデルに効率よくコピーする手法」 とされます。
(吉田ハンチング@dcp)